Học không giám sát, hay Unsupervised Learning, là một nhánh của học máy (machine learning) nơi mô hình AI tự tìm kiếm các mẫu hoặc cấu trúc ẩn trong dữ liệu mà không cần được cung cấp nhãn (label) trước. Khác với học có giám sát (Supervised Learning) yêu cầu dữ liệu đã được gắn nhãn, học không giám sát làm việc với dữ liệu thô, giúp khám phá các mối quan hệ hoặc nhóm mà không cần hướng dẫn cụ thể.
Ví dụ, nếu bạn có dữ liệu về hành vi mua sắm của khách hàng, học không giám sát có thể tự động chia khách hàng thành các nhóm dựa trên sở thích, như “người mua đồ thể thao” hoặc “người yêu thích thời trang cao cấp”, mà không cần bạn xác định trước các nhóm này.
Minh họa dữ liệu được phân cụm tự động, giúp hiểu rõ học không giám sát là gì
Tại sao học không giám sát quan trọng?
Học không giám sát đóng vai trò quan trọng trong AI vì:
Xử lý dữ liệu thô: Hầu hết dữ liệu trong thế giới thực không có nhãn, và học không giám sát giúp khai thác giá trị từ chúng.
Khám phá mẫu ẩn: Tìm ra các xu hướng hoặc đặc điểm mà con người có thể bỏ qua.
Tiết kiệm chi phí: Không cần gắn nhãn dữ liệu, giảm thời gian và nguồn lực.
Ứng dụng đa dạng: Từ phân tích thị trường đến phát hiện bất thường, học không giám sát có thể áp dụng trong nhiều lĩnh vực.
Đây là lý do vì sao thuật toán không giám sát đang được các doanh nghiệp và nhà nghiên cứu sử dụng rộng rãi.
Ý định tìm kiếm của người dùng với từ khóa “Học không giám sát”
Khi tìm kiếm “học không giám sát”, người dùng thường muốn:
Hiểu rõ học không giám sát là gì và cách nó khác với các loại học máy khác.
Tìm ví dụ về thuật toán không giám sát và cách chúng hoạt động.
Biết cách áp dụng học không giám sát, đặc biệt trong phân cụm hoặc phát hiện bất thường.
Khám phá các ứng dụng thực tế và lợi ích của học không giám sát.
Tìm tài nguyên để học thêm về chủ đề này.
Bài viết này sẽ cung cấp thông tin toàn diện, từ khái niệm cơ bản đến ứng dụng thực tiễn, giúp bạn nắm vững học không giám sát.
Sự khác biệt giữa học không giám sát và các loại học máy khác
Để hiểu rõ hơn về học không giám sát là gì, hãy so sánh với các loại học máy khác:
Học có giám sát (Supervised Learning): Sử dụng dữ liệu đã gắn nhãn để dự đoán, như phân loại email là spam hay không spam.
Học không giám sát (Unsupervised Learning): Làm việc với dữ liệu không có nhãn, tìm kiếm mẫu hoặc nhóm, như phân cụm khách hàng.
Học tăng cường (Reinforcement Learning): Học qua thử và sai để tối ưu hóa hành động, như AI chơi cờ vua.
Học không giám sát phù hợp khi bạn muốn khám phá dữ liệu mà không biết trước kết quả mong muốn.
Các loại thuật toán không giám sát
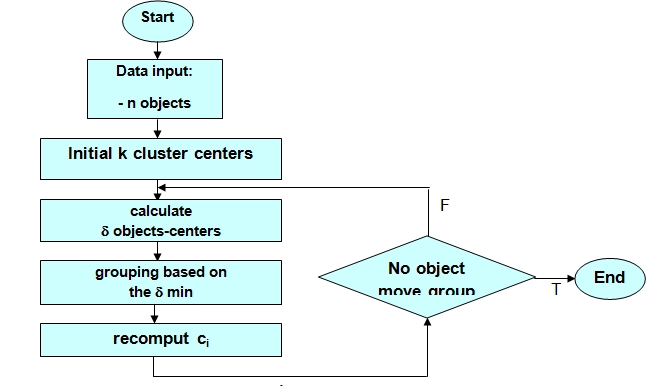
Thuật toán không giám sát được chia thành hai nhóm chính: phân cụm và giảm chiều dữ liệu. Dưới đây là các thuật toán phổ biến:
Phân cụm (Clustering)
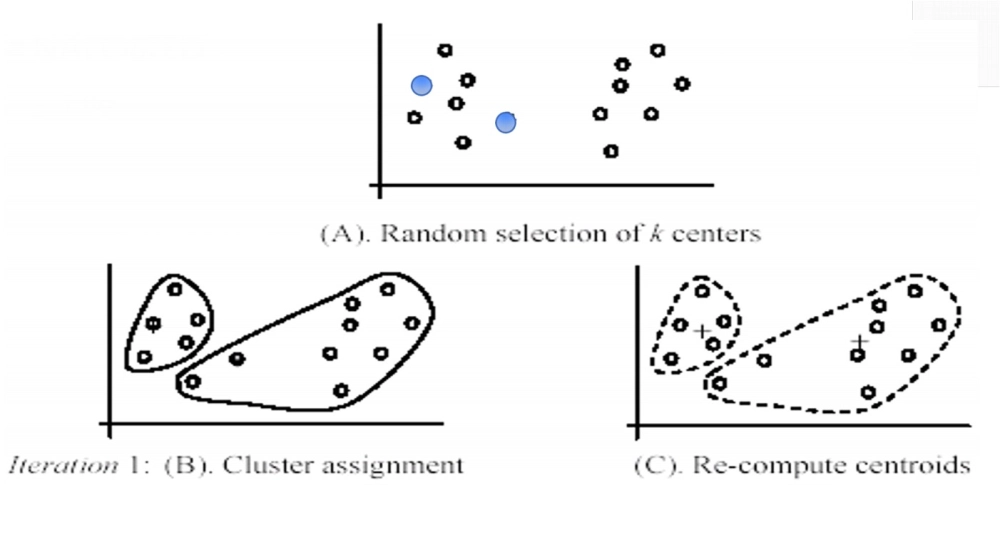
K-Means: Phân chia dữ liệu thành K nhóm dựa trên sự tương đồng. Ví dụ, phân nhóm khách hàng theo hành vi mua sắm.
Hierarchical Clustering: Xây dựng cây phân cấp để nhóm dữ liệu, hữu ích trong phân tích dữ liệu sinh học.
DBSCAN: Tìm các cụm dựa trên mật độ, phù hợp để phát hiện bất thường.
Giảm chiều dữ liệu (Dimensionality Reduction)
PCA (Principal Component Analysis): Giảm số chiều của dữ liệu, giữ lại các đặc điểm quan trọng.
t-SNE: Dùng để trực quan hóa dữ liệu phức tạp, như hiển thị dữ liệu trên biểu đồ 2D.
Autoencoders: Mạng nơ-ron dùng để nén và tái tạo dữ liệu, thường dùng trong xử lý ảnh.
Biểu đồ phân cụm K-Means, minh họa cách hoạt động của thuật toán không giám sát
Cách học không giám sát hoạt động
Học không giám sát dựa trên việc tìm kiếm mẫu hoặc cấu trúc trong dữ liệu. Quy trình cơ bản bao gồm:
Thu thập dữ liệu: Dữ liệu thô, không cần nhãn, như lịch sử mua hàng hoặc hình ảnh.
Chọn thuật toán: Quyết định sử dụng thuật toán phân cụm hay giảm chiều tùy vào mục tiêu.
Huấn luyện mô hình: Mô hình tự động tìm các mẫu hoặc nhóm trong dữ liệu.
Phân tích kết quả: Kiểm tra các cụm hoặc đặc điểm được phát hiện để áp dụng vào thực tế.
Ví dụ, để phân tích thị trường, bạn có thể dùng K-Means để nhóm khách hàng theo hành vi, từ đó thiết kế các chiến dịch marketing nhắm mục tiêu.
Ứng dụng thực tế của học không giám sát
Học không giám sát được sử dụng rộng rãi trong nhiều ngành:
Kinh doanh
Phân khúc khách hàng: Phân cụm khách hàng để tối ưu hóa chiến lược marketing.
Gợi ý sản phẩm: Hệ thống đề xuất như Amazon sử dụng học không giám sát để tìm các sản phẩm tương tự.
Phát hiện gian lận: Xác định các giao dịch bất thường dựa trên mẫu dữ liệu.
Y tế
Phân tích hình ảnh y khoa: Nhóm các mẫu hình ảnh để phát hiện bệnh, như ung thư.
Phân loại bệnh nhân: Phân cụm bệnh nhân theo triệu chứng để cá nhân hóa điều trị.
Công nghệ
Xử lý ngôn ngữ tự nhiên: Nhóm các tài liệu hoặc bài viết dựa trên chủ đề.
Xử lý ảnh: Giảm chiều dữ liệu để nén ảnh hoặc phát hiện đặc điểm.
Khoa học
Phân tích dữ liệu gen: Nhóm các gen hoặc protein tương đồng để nghiên cứu sinh học.
Khám phá thiên văn: Phát hiện các mẫu trong dữ liệu vũ trụ, như nhóm các ngôi sao.
Phân cụm khách hàng trong marketing, phân cụm trong học không giám sát
Lợi ích của học không giám sát
Học không giám sát mang lại nhiều giá trị:
Khám phá dữ liệu mới: Tìm ra các xu hướng hoặc mẫu mà con người không nhận ra.
Tiết kiệm thời gian: Không cần gắn nhãn dữ liệu, giảm công sức chuẩn bị.
Linh hoạt: Áp dụng được cho nhiều loại dữ liệu, từ văn bản đến hình ảnh.
Hỗ trợ quyết định: Cung cấp thông tin chi tiết để ra quyết định kinh doanh hoặc khoa học.
Ví dụ, một công ty thương mại điện tử có thể sử dụng phân cụm để tìm ra nhóm khách hàng tiềm năng mà không cần phân tích thủ công.
Hạn chế của học không giám sát
Dù mạnh mẽ, học không giám sát vẫn có một số hạn chế:
Khó đánh giá kết quả: Vì không có nhãn, khó xác định kết quả có chính xác hay không.
Phụ thuộc vào dữ liệu: Dữ liệu chất lượng thấp có thể dẫn đến kết quả sai lệch.
Tính phức tạp: Một số thuật toán, như DBSCAN, yêu cầu điều chỉnh tham số cẩn thận.
Khó giải thích: Kết quả phân cụm đôi khi khó diễn giải cho người không chuyên.
Hiểu rõ những hạn chế này giúp bạn sử dụng thuật toán không giám sát một cách hiệu quả hơn.
Cách bắt đầu với học không giám sát
Nếu bạn muốn thử nghiệm học không giám sát, hãy làm theo các bước sau:
Học cơ bản về học máy: Nắm vững các khái niệm nhưphân cụm và giảm chiều.
Chọn công cụ: Sử dụng các thư viện như Scikit-learn (Python), TensorFlow, hoặc R.
Tìm dữ liệu: Thu thập dữ liệu thô, như lịch sử mua sắm hoặc hình ảnh.
Thử nghiệm thuật toán: Bắt đầu với K-Means hoặc PCA để làm quen.
Phân tích và tối ưu: Kiểm tra kết quả và điều chỉnh tham số để cải thiện.
Giao diện Scikit-learn chạy thuật toán K-Means, minh họa thuật toán không giám sát
So sánh học không giám sát với các phương pháp khác
Học không giám sát vs học có giám sát
Học không giám sát: Không cần nhãn, tập trung vào khám phá mẫu.
Học có giám sát: Cần nhãn, tập trung vào dự đoán chính xác.
Học không giám sát vs học tăng cường
Học không giám sát: Tìm mẫu trong dữ liệu tĩnh.
Học tăng cường: Học qua tương tác với môi trường để tối ưu hóa hành động.
Học không giám sát phù hợp khi bạn muốn khám phá dữ liệu mà không có mục tiêu cụ thể.
Tài nguyên học về học không giám sát
Để tìm hiểu thêm về học không giám sát là gì, bạn có thể tham khảo:
Sách: “Pattern Recognition and Machine Learning” của Christopher Bishop.
Khóa học: Các khóa học trên Coursera, edX, hoặc Udemy về học máy.
Blog: Theo dõi Towards Data Science hoặc Google AI Blog.
Thư viện: Sử dụng Scikit-learn, TensorFlow, hoặc PyTorch để thực hành.
Khóa học trực tuyến về học máy
Tương lai của học không giám sát
Học không giám sát sẽ tiếp tục phát triển với:
Cải thiện thuật toán: Các thuật toán mới sẽ hiệu quả hơn, yêu cầu ít dữ liệu hơn.
Tích hợp với AI mạnh: Học không giám sát là bước đệm để đạt tới trí tuệ nhân tạo tổng quát (AGI).
Ứng dụng rộng rãi: Từ xe tự hành đến phân tích dữ liệu lớn, học không giám sát sẽ mở rộng phạm vi ảnh hưởng.
Việc đầu tư vào thuật toán không giám sát sẽ giúp doanh nghiệp và nhà nghiên cứu khai thác tối đa dữ liệu trong tương lai.
Kết luận
Học không giám sát là một công cụ mạnh mẽ giúp khám phá các mẫu ẩn trong dữ liệu, từ phân cụm khách hàng đến phát hiện bất thường. Dù có những hạn chế, thuật toán không giám sát mang lại giá trị to lớn trong kinh doanh, y tế, và khoa học. Bằng cách hiểu rõ học không giám sát là gì và cách áp dụng nó, bạn có thể tận dụng công nghệ này để đưa ra quyết định thông minh hơn. Bắt đầu khám phá học không giám sát ngay hôm nay để mở khóa tiềm năng của dữ liệu!





Bình Luận