Bạn có bao giờ tự hỏi làm thế nào AI có thể tự học cách chơi game giỏi hơn cả con người hay điều khiển robot một cách thông minh? Câu trả lời nằm ở học tăng cường (Reinforcement Learning - RL), một nhánh của trí tuệ nhân tạo (AI) nơi máy móc học hỏi từ kinh nghiệm thông qua thử và sai. RL là gì? Nói đơn giản, đó là quá trình máy học cách đưa ra quyết định tối ưu bằng cách thử nghiệm, nhận phản hồi từ môi trường và cải thiện hành động của mình.
Hãy tưởng tượng bạn dạy một chú chó làm xiếc: mỗi lần chú chó thực hiện đúng, bạn thưởng bánh quy; nếu sai, bạn không thưởng. Học tăng cường hoạt động tương tự, nhưng thay vì bánh quy, AI nhận được “phần thưởng” từ một hàm đánh giá. Phương pháp này giúp AI tìm ra chiến lược tốt nhất trong các tình huống phức tạp, từ chơi cờ vua đến tối ưu hóa chuỗi cung ứng.

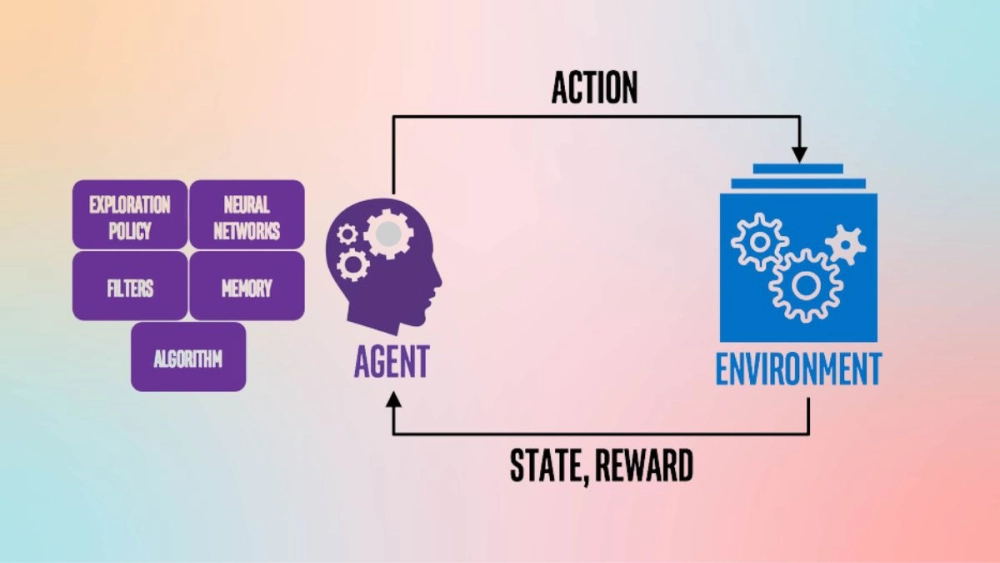
Học tăng cường dựa trên một vòng lặp đơn giản nhưng mạnh mẽ: tác nhân (agent), môi trường (environment), hành động (action), phần thưởng (reward) và trạng thái (state). Hãy chia nhỏ cách nó hoạt động:
Quá trình này lặp đi lặp lại: tác nhân thực hiện hành động, nhận phần thưởng, cập nhật kiến thức và chọn hành động tốt hơn ở lần sau. Mục tiêu là tối đa hóa tổng phần thưởng theo thời gian.
Để biến học tăng cường thành hiện thực, các nhà khoa học đã phát triển nhiều thuật toán học tăng cường. Dưới đây là một số thuật toán nổi bật:
Mỗi thuật toán có ưu và nhược điểm riêng, tùy thuộc vào môi trường và mục tiêu cụ thể. Ví dụ, DQN rất hiệu quả trong các trò chơi như Atari, trong khi PPO thường được dùng trong điều khiển robot.
Học tăng cường không chỉ là lý thuyết mà đã được áp dụng trong nhiều lĩnh vực, mang lại giá trị to lớn. Dưới đây là một số ứng dụng RL nổi bật:
Học tăng cường đã tạo nên những kỳ tích trong thế giới game. Ví dụ, AlphaGo của DeepMind sử dụng RL để đánh bại các nhà vô địch cờ vây thế giới. Tương tự, các hệ thống RL đã học cách chơi các trò chơi như Dota 2 và StarCraft II ở cấp độ chuyên nghiệp.
Xe tự lái sử dụng RL để học cách điều hướng trong môi trường phức tạp, từ việc tránh chướng ngại vật đến tối ưu hóa lộ trình. Các thuật toán RL giúp xe đưa ra quyết định trong thời gian thực, như tăng tốc hay phanh.
Trong y tế, RL được sử dụng để tối ưu hóa kế hoạch điều trị. Ví dụ, AI có thể đề xuất liều lượng thuốc phù hợp cho từng bệnh nhân dựa trên dữ liệu y khoa, giúp tăng hiệu quả điều trị và giảm tác dụng phụ.
Robot sử dụng RL để học các nhiệm vụ như cầm nắm đồ vật, di chuyển trong không gian không xác định hoặc lắp ráp sản phẩm. Điều này đặc biệt hữu ích trong các nhà máy thông minh.
RL giúp tối ưu hóa việc sử dụng năng lượng trong các tòa nhà thông minh, quản lý chuỗi cung ứng hoặc phân bổ tài nguyên trong các hệ thống viễn thông.
Chú thích ảnh: Ứng dụng của ứng dụng RL trong xe tự lái, minh họa cách AI học cách điều hướng trên đường phố đông đúc.
Mặc dù đầy tiềm năng, học tăng cường cũng đối mặt với nhiều thách thức:

Nếu bạn muốn tìm hiểu hoặc áp dụng học tăng cường, dưới đây là một số bước cơ bản:

Học tăng cường đang phát triển nhanh chóng và hứa hẹn sẽ tiếp tục cách mạng hóa nhiều lĩnh vực. Một số xu hướng tương lai bao gồm:
Với sự phát triển của công nghệ, học tăng cường có thể trở thành nền tảng cho những hệ thống AI thông minh hơn, linh hoạt hơn và gần gũi hơn với con người.
Học tăng cường là một lĩnh vực đầy tiềm năng, mở ra cánh cửa cho những ứng dụng AI thông minh và tự chủ. Từ việc chơi game, lái xe tự động đến tối ưu hóa y tế, ứng dụng RL đang thay đổi cách chúng ta tương tác với công nghệ. Bằng cách hiểu rõ RL là gì, các thuật toán học tăng cường và những thách thức liên quan, bạn có thể bắt đầu hành trình khám phá lĩnh vực này. Bạn đã sẵn sàng để thử sức với học tăng cường chưa? Hãy bắt đầu với một môi trường đơn giản và để trí tò mò dẫn đường!
Xem thêm:
Tìm hiểu AI giải thích được Minh bạch trong trí tuệ nhân tạo




Bình Luận