Bạn có bao giờ tự hỏi trí tuệ nhân tạo (AI) học hỏi như thế nào mà không cần con người hướng dẫn từng bước? Học không giám sát chính là chìa khóa mở ra cánh cửa kỳ diệu của AI, nơi máy móc tự tìm ra các mẫu và mối quan hệ trong dữ liệu mà không cần nhãn hay chỉ dẫn. Từ việc phân tích hành vi khách hàng đến phát hiện gian lận, công nghệ này đang thay đổi cách chúng ta tương tác với thế giới số. Trong bài viết này, chúng ta sẽ khám phá học không giám sát là gì, cách các thuật toán không giám sát hoạt động, và vai trò của phân cụm trong việc định hình tương lai AI. Hãy cùng bắt đầu hành trình khám phá này!
Học không giám sát là một nhánh của học máy, nơi máy tính tự học từ dữ liệu mà không cần được cung cấp nhãn hay thông tin đầu ra cụ thể. Khác với học có giám sát (supervised learning), nơi máy được “dạy” bằng các ví dụ đã được gắn nhãn, học không giám sát cho phép máy tự tìm ra cấu trúc ẩn trong dữ liệu. Điều này đặc biệt hữu ích khi chúng ta có khối lượng dữ liệu khổng lồ nhưng không có thời gian hay nguồn lực để gắn nhãn thủ công. Ví dụ, các công ty thương mại điện tử sử dụng học không giám sát để phân nhóm khách hàng dựa trên thói quen mua sắm.
Học không giám sát không chỉ là một khái niệm kỹ thuật mà còn là nền tảng cho nhiều ứng dụng thực tế, từ xử lý ngôn ngữ tự nhiên đến phân tích hình ảnh. Nó mang lại sự linh hoạt, tiết kiệm thời gian và chi phí, đồng thời mở ra cơ hội khám phá những hiểu biết mới mà con người có thể bỏ sót.

Unsupervised learning là một nhánh quan trọng của Machine learning
Học không giám sát bắt nguồn từ những năm 1950, khi các nhà khoa học máy tính bắt đầu khám phá cách máy móc có thể tự tìm ra các mẫu trong dữ liệu. Những thuật toán ban đầu, như phân cụm K-means, được phát triển để nhóm dữ liệu dựa trên sự tương đồng mà không cần nhãn. Đây là bước đầu tiên để máy tính “tự học” mà không cần con người can thiệp.
Vào cuối thế kỷ 20, các thuật toán không giám sát như PCA (Principal Component Analysis) và t-SNE ra đời, giúp giảm chiều dữ liệu và trực quan hóa thông tin phức tạp. Những tiến bộ này đã mở đường cho việc áp dụng học không giám sát trong các lĩnh vực như y học và tài chính.
Ngày nay, học không giám sát là một phần không thể thiếu trong các mô hình AI tiên tiến. Với sự phát triển của mạng nơ-ron và học sâu, các thuật toán như autoencoders và GANs (Generative Adversarial Networks) đã nâng cao khả năng của học không giám sát, từ tạo hình ảnh chân thực đến phân tích dữ liệu lớn.
Học không giám sát là gì? Đây là câu hỏi mà nhiều người, từ sinh viên đến doanh nghiệp, đều muốn tìm hiểu. Nói một cách đơn giản, học không giám sát là quá trình máy tính tự phân tích dữ liệu thô để tìm ra các mẫu, xu hướng hoặc nhóm mà không cần hướng dẫn trước. Hãy tưởng tượng bạn giao cho máy tính một hộp đầy các mảnh ghép không có hướng dẫn – nó sẽ tự tìm cách sắp xếp chúng thành một bức tranh hoàn chỉnh.
 Unsupervised learning hoạt động dựa trên thuật toán tự học
Unsupervised learning hoạt động dựa trên thuật toán tự học
Thuật toán không giám sát là trái tim của học không giám sát, giúp máy tính phân tích và xử lý dữ liệu một cách thông minh. Các thuật toán này được thiết kế để tìm ra cấu trúc ẩn trong dữ liệu mà không cần nhãn. Một số thuật toán phổ biến bao gồm K-means, DBSCAN, và PCA, mỗi loại có điểm mạnh và ứng dụng riêng.
Các thuật toán không giám sát được sử dụng rộng rãi trong nhiều ngành. Ví dụ, trong y học, chúng giúp phân tích dữ liệu hình ảnh y tế để phát hiện bệnh sớm. Trong thương mại điện tử, chúng tối ưu hóa hệ thống khuyến nghị sản phẩm. Để tìm hiểu thêm về các thuật toán này, bạn có thể tham khảo trang web của MIT về học máy.
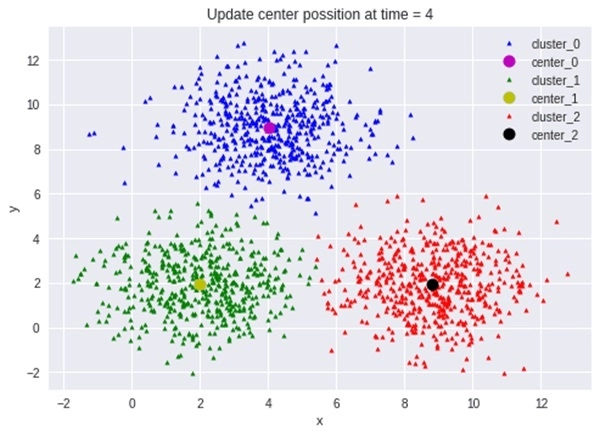
Thuật toán phân cụm được ứng dụng rộng rãi trong nhiều lĩnh vực
Phân cụm là một trong những kỹ thuật quan trọng nhất của học không giám sát, nơi dữ liệu được nhóm thành các cụm dựa trên sự tương đồng. Kỹ thuật này giúp khám phá các mẫu ẩn trong dữ liệu mà không cần nhãn, từ đó hỗ trợ ra quyết định trong nhiều lĩnh vực.
Phân cụm hoạt động bằng cách đo lường khoảng cách hoặc sự tương đồng giữa các điểm dữ liệu. Các thuật toán như K-means hoặc DBSCAN sẽ nhóm các điểm dữ liệu gần nhau thành một cụm, giúp phân tích và hiểu dữ liệu dễ dàng hơn.

Ứng dụng Unsupervised learning trong nhận diện hình ảnh
Học không giám sát là một bước tiến vượt bậc trong lĩnh vực trí tuệ nhân tạo, mở ra khả năng khám phá các mẫu ẩn mà không cần sự can thiệp của con người. Từ việc tìm hiểu học không giám sát là gì, khám phá các thuật toán không giám sát, đến ứng dụng phân cụm trong thực tế, công nghệ này đã và đang thay đổi cách chúng ta xử lý dữ liệu. Đối với doanh nghiệp, kỹ thuật viên, hay sinh viên, việc hiểu và áp dụng học không giám sát có thể mang lại lợi thế cạnh tranh đáng kể.
Hãy bắt đầu khám phá học không giám sát ngay hôm nay! Bạn có thể thử áp dụng các thuật toán như K-means hoặc tìm hiểu thêm về các ứng dụng thực tế để nâng cao kiến thức và kỹ năng của mình. Công nghệ AI đang phát triển nhanh chóng, và học không giám sát chính là chìa khóa để bạn không bị tụt hậu.
CTA: Bạn muốn tìm hiểu thêm về AI và học không giám sát? Hãy theo dõi blog của chúng tôi để cập nhật những bài viết mới nhất!
1. Học không giám sát là gì?
Học không giám sát là một phương pháp học máy nơi máy tính tự tìm ra các mẫu trong dữ liệu mà không cần nhãn hay hướng dẫn.
2. Học không giám sát khác gì với học có giám sát?
Học không giám sát không cần dữ liệu có nhãn, trong khi học có giám sát yêu cầu dữ liệu được gắn nhãn để đào tạo mô hình.
3. Các thuật toán không giám sát phổ biến nhất là gì?
Một số thuật toán phổ biến bao gồm K-means, DBSCAN, PCA, autoencoders và GANs, được sử dụng trong nhiều ứng dụng khác nhau.
4. Phân cụm được sử dụng như thế nào trong thực tế?
Phân cụm được dùng để nhóm khách hàng, phát hiện bất thường, hoặc phân loại bệnh nhân trong y học dựa trên dữ liệu.
5. Học không giám sát có nhược điểm gì?
Kết quả của học không giám sát có thể khó diễn giải và đôi khi cần nhiều tài nguyên tính toán để đạt hiệu quả.
6. Làm thế nào để bắt đầu học về học không giám sát?
Bạn có thể bắt đầu bằng cách học các thuật toán cơ bản như K-means, tham gia khóa học AI, hoặc thực hành với dữ liệu thực tế.




Bình Luận